Hire me
Articles
February 8, 2017
Using Travis CI for Rails + Node.js
How to set up travis.yml for multiple languages
November 26, 2016
Joining Toptal
Freelancing & remoting
August 20, 2015
React + Webpack + Karma + Express = ♥
First steps & minimal setup
August 20, 2015
Multiple apps on 1 dokku droplet
With subdomains, on Digital Ocean
May 8, 2015
Social pomodoro Berlin
Creating & relaxing together
May 8, 2015
New city, new blog
.
February 25, 2013
Locking to a specific Firefox release in specs
when testing Rails with Capybara & Selenium
February 12, 2013
Decoupling feature specs from markup
Simple guidelines for resilient tests
January 16, 2013
Faster feature specs with authentication
Make specs more efficient to write and execute
August 2, 2012
kubuntu 12.04 Precise 64bits reinstall notes
On my Dell XPS m1530
July 21, 2012
Fetch images from Flickr
And show them in Octopress/Jekyll
October 20, 2011
Opening Photoshop .psd files in Ubuntu
(With Ubuntu 11.10 Oneiric Ocelot)
January 20, 2011
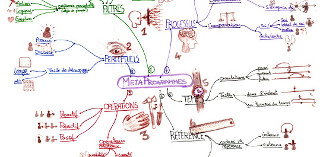
Métaprogrammes en PNL
Mindmap
Crafted with
by
Daniel Reszka
who lives and works in Berlin building useful things.
You should follow him on social media
.